| **Erweiterung** | **Beschreibung** | **Einsatzzweck** |
|---|---|---|
| **Prettier** | Automatisches Codeformatierungs-Tool. Definiert einheitlichen Stil für z. B. Einrückung, Semikolons. | Formatierung & Clean Code |
| **ESLint** | Linter zur statischen Analyse von JavaScript/TypeScript-Code. Findet potenzielle Fehler & Stilprobleme. | Codequalität und Fehlervorbeugung |
| **Vitest** | Schnelles Unit-Testing-Framework, optimiert für Vite und moderne Frontends. | Komponententests, Logiktests |
| **Playwright** | Framework für End-to-End-Tests. Ermöglicht UI-Tests mit echten Browserinstanzen. | Testen von Userflows & Accessibility |
| **TailwindCSS** | Utility-first CSS-Framework für schnelles und responsives Styling. | Styling über Utility-Klassen |
| **SvelteKit Adapter** | Bindeglied zwischen dem Framework und der Zielplattform (z. B. statisches HTML, SSR, Vercel etc.). | Deployment-Anpassung |
| **Drizzle** | TypeScript-ORM für SQL-Datenbanken mit gutem DX. | Datenbankzugriff (PostgreSQL etc.) |
| **Lucia** | Authentifizierungs-Framework mit Fokus auf Einfachheit und Sicherheit. | Login-Mechanismen, Zugriffskontrolle |
| **mdsvex** | Markdown-Präprozessor für Svelte-Komponenten. Kombination von Markdown und Svelte möglich. | Content Management, Dokusysteme |
| **Paraglide** | Internationalisierungs-Tool mit Compile-Time-Optimierung. | Mehrsprachigkeit (i18n) |
| **Storybook** | Tool zur Visualisierung und Dokumentation einzelner UI-Komponenten. | Komponentenkatalog & Dokumentation |
| **Plugin** | **Beschreibung** |
|---|---|
| **Typography** | Stellt sinnvolle Standard-Styles für typografische Inhalte bereit. Eignet sich besonders für Content-lastige Seiten, z. B. Dokumentation oder Blogbeiträge. |
| **Forms** | Vereinheitlicht das Styling von nativen HTML-Formular-Elementen wie input, select, textarea etc. Passt sich automatisch an das Tailwind-Designsystem an. |
| **Adapter** | **Beschreibung** | **Typ** | **Empfohlene Einsatzzwecke** |
|---|---|---|---|
| **auto** | Automatische Auswahl anhand der Umgebung. Praktisch für Entwicklung, aber nicht für produktives Deployment empfohlen. | auto-detect | Nur lokale Nutzung, z. B. für Tests |
| **node** | Erstellt ein Node.js-Handler zur Laufzeit, z. B. für Express, Fastify oder Cloud-Server. | SSR | Eigener Serverbetrieb, z. B. VPS, Docker-Container |
| **static** | Exportiert alle Seiten als HTML/CSS/JS. Kein dynamisches Routing, aber sehr performant. | SSG (Static Site) | GitHub Pages, Netlify, klassische Webserver |
| **vercel** | Optimierung für das Vercel-Ökosystem. Deployment erfolgt über Vercel CLI oder GitHub-Integration. | Edge-/SSR-ready | Hosting über [vercel.com](https://vercel.com) |
| **cloudflare-pages** | Unterstützung für Cloudflare Pages, inkl. Worker-Skripte. | Edge SSR | Deployment auf [pages.cloudflare.com](https://pages.cloudflare.com) |
| **netlify** | Adapter mit Funktionen wie Functions, Redirects, SSR via Netlify. | Hybrid | Deployment auf [netlify.com](https://www.netlify.com) |
| **Pfad** | **Beschreibung** |
|---|---|
| src/routes/ | Implementierung der Seitenstruktur der Anwendung. Jede Datei oder jeder Ordner stellt eine Route dar. |
| src/routes/+page.svelte | Einstiegspunkt der Anwendung (Startseite, Route /). Kann sofort bearbeitet werden. |
| src/lib/ | Globale Hilfsmittel, z. B. Komponenten, Stores, Services. Nicht Routen-spezifisch. |
| src/app.css | Haupt-Stylesheet. Hier wird TailwindCSS eingebunden (@tailwind base, components, utilities). |
| static/ | Enthält öffentlich zugängliche Dateien (z. B. robots.txt, favicon.ico, statische Bilder). |
| svelte.config.js | Konfiguriert Adapter, Preprocessing, Pfade etc. |
| tailwind.config.cjs | Definiert Tailwind-Themes, Plugins und Pfade zur Content-Erkennung. |
| tsconfig.json | Konfiguriert das Verhalten des TypeScript-Compilers. |
Keine useState-Calls, keine riesige API – nur schlankes HTML & JavaScript.
TODO: - Dateibenennung - Import/Export von Komponenten/Modulen - *Runes* im Detail - TypeScript-Support # Styling & UX mit Tailwind CSS Tailwind CSS passt hervorragend zu Svelte. Es erlaubt schnelles Prototyping, konsistentes Design und volle Kontrolle direkt im Markup. ``` ``` TODO: - Verweis auf Installation mit SvelteKit - Dev- vs. Build-Mode # Beispielaufgabe: Vier Gewinnt In dieser Beispielaufgabe entwickeln wir eine einfache Webanwendung mit **SvelteKit**, die das klassische Spiel „Vier Gewinnt“ als lokale Zwei-Spieler-Variante umsetzt. Diese Version enthält ausschließlich Frontend-Logik und basiert auf dem **Static Adapter** von SvelteKit. Sie bildet die Grundlage für die spätere Erweiterung um eine Multiplayer-Funktion mit Datenbankanbindung im nächsten Kapitel. ### Zielsetzung Ziel dieser Aufgabe ist es, ein funktionierendes Spiel zu bauen, das komplett im Browser läuft, keine Verbindung zu einem Server benötigt und als statische Website bereitgestellt werden kann. Die Umsetzung soll die Stärken von **Svelte** bei der Entwicklung interaktiver Komponenten demonstrieren und gleichzeitig ein übersichtliches Projekt mit nachvollziehbarer Struktur liefern. ### Projektgrundlage Wir starten mit der Initialisierung eines neuen SvelteKit-Projekts. Dafür verwenden wir das SvelteKit CLI. ``` npm create svelte@latest vier-gewinnt-frontend ``` Im Setup wählen wir das SvelteKit minimal Setup, aktivieren TypeScript, ESLint, Prettier, Tailwind CSS und wir installieren wir den Static Adapter. Eine genauere Dokumentation des CLI findest du in dem Artikel [Projektsetup mit SvelteKit](https://wiki.kleinform.at/books/advanced-web-technologies-wiki-zum-mastermodul/page/projektsetup-mit-sveltekit "Projektsetup mit SvelteKit"). Um die Anwendung während der Entwicklung im Browser zu testen, starten wir den Entwicklungsserver: ``` npm run dev --open ``` ### Projektstruktur Der Einstiegspunkt für unsere Anwendung befindet sich in der Datei `src/routes/+page.svelte`. In dieser Komponente schreiben wir sowohl die Spiellogik als auch das HTML-Markup und das grundlegende Styling direkt in einer Datei. Für diese Frontend-Version verzichten wir bewusst auf eine Aufteilung in mehrere Komponenten – das reduziert vorerst die Komplexität. Im Projektverzeichnis befinden sich zahlreiche Dateien und Ordner, von denen für diese Aufgabe nur wenige eine Rolle spielen: ``` vier-gewinnt-frontend/ ├── src/ │ ├── app.css │ └── routes/ │ ├── +layout.svelte ← gemeinsames Layout aller Seiten │ ├── +layout.ts ← legt fest, dass das Projekt prerenderbar ist │ └── +page.svelte ← Hauptdatei mit Spiellogik und UI ├── svelte.config.js ├── package.json └── ... ``` #### Die Rolle von +layout.svelte Die Datei `+layout.svelte` ist bei SvelteKit der Standardort für gemeinsame Layouts, die auf allen Seiten einer Route (hier: `/`) angezeigt werden sollen. In unserem Fall nutzen wir sie, um globale Styles (`app.css`) einzubinden und das allgemeine Layout der Seite zu definieren – z. B. zentrierte Inhalte, Container-Breiten oder Hintergrundfarben. ```Spieler {winner} hat gewonnen!
{:else}Am Zug: Spieler {currentPlayer}
{/if} ``` #### Dateibasierte Routen Ein weiterer wichtiger Aspekt von SvelteKit ist das **Dateisystem-basierte Routing**. Jede Datei im Ordner `src/routes` entspricht automatisch einer URL. In unserem Fall: - src/routes/+page.svelte → / - src/routes/+layout.svelte → gemeinsames Layout für alle Unterseiten Dieses Routing-Prinzip reduziert die Komplexität im Vergleich zu klassischen Router-Konfigurationen erheblich. #### Empfehlung: Code ansehen & selbst ausprobieren Ich empfehle, den Code einmal vollständig durchzugehen oder lokal auszuführen, um diese Konzepte selbst auszuprobieren und besser zu verstehen. 👉 [Zum vollständigen Code auf GitLab](https://gitlab.rlp.net/marius.klein2/awt-marius-klein/-/tree/main/beispielaufgaben/vier-gewinnt) ### Build & Deploy Beim Einsatz des Static Adapters müssen wir SvelteKit explizit mitteilen, dass Seiten **statisch generiert** werden dürfen. Das geschieht über eine Datei `+layout.ts`. ``` vier-gewinnt-frontend/ ├── src/ │ ├── app.css │ └── routes/ │ ├── +layout.svelte │ ├── +layout.ts ← muss hier erstellt werden │ └── +page.svelte ├── svelte.config.js ├── package.json └── ... ``` In der in der `+layout.ts` müssen wir export `const prerender = true` setzen: ``` // src/routes/+layout.ts export const prerender = true; ``` Ohne diese Angabe bleibt SvelteKit im „SSR-Modus“ und erzeugt keine statischen HTML-Dateien beim Build. Für die Frontend-only-Version ist das jedoch notwendig. Jetzt kann das Projekt gebaut werden: ``` npm run build ``` Der HTML-Code befindet sich danach im Ordner `build` und kann direkt auf einen Webserver geladen werden. # Exkurs: 3D-Anwendungen im Handumdrehen mit Threlte ```bash npm install three @threlte/core @threlte/extras ``` # Backend-Technologien # Mein Weg zu PayloadCMS: Backend-Vergleich aus der Praxis In meinem Projekt stand ich vor der Aufgabe, ein modernes CMS aufzusetzen – mit möglichst viel Flexibilität, einem angenehmen Workflow und gutem API-Zugriff. Hier dokumentiere ich meine Evaluierung verschiedener Backend-Technologien und Frameworks – und wie ich schließlich bei **PayloadCMS** gelandet bin. [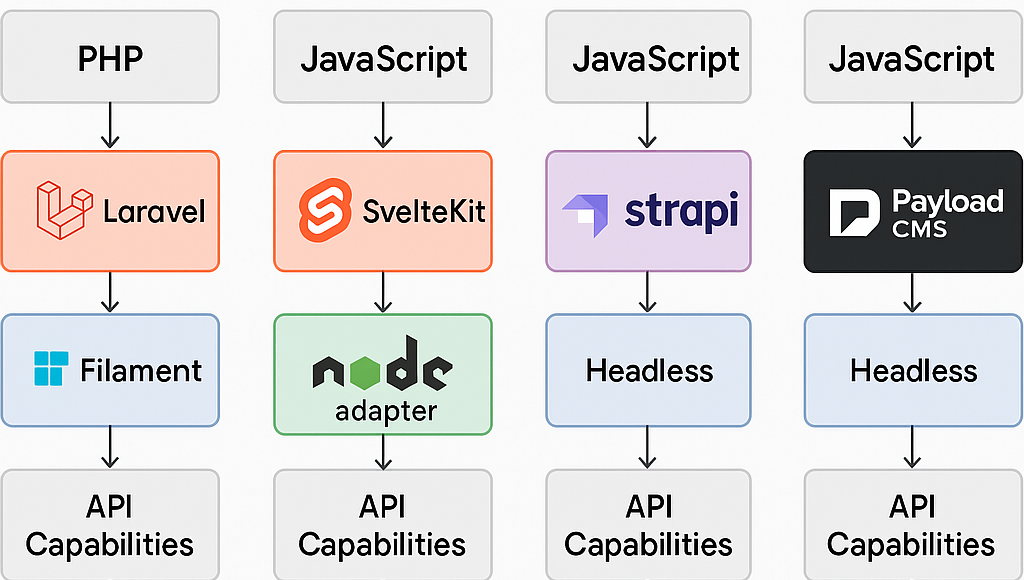](https://wiki.kleinform.at/uploads/images/gallery/2025-04/963qIpU63EgeBb34-ubersicht.png) ### Laravel (PHP) – Stark, aber überdimensioniert und etwas altbacken? **Was mir gefallen hat:** Laravel ist mächtig. Besonders das Eloquent ORM und das Ecosystem (Jobs, Queues, Policies etc.) bieten viele Features direkt „out of the box“. Mit **Filament** steht zudem ein sehr starkes Admin-Panel-Toolkit zur Verfügung. **Aber:** - Für ein CMS war mir das Setup oft zu schwergewichtig. - PHP ist für viele Dinge okay – aber die Arbeit mit JSON, REST oder modernen Frontend-Workflows wirkt oft sperriger als bei node-basierten Lösungen. - Auch das Hosting (z. B. auf Vercel oder Netlify) ist nicht ganz so smooth wie mit JavaScript-Stacks. **Fazit:** Ein tolles Framework, aber für mein Ziel „Headless CMS mit modernem JS-Frontend“ war es nicht die erste Wahl. ### SvelteKit – Elegantes Frontend, aber keine komplexen Backend-Lösungen **Was ich mochte:** SvelteKit ist superschnell, modern und macht Spaß. Besonders die neue V5 ist sehr spannend für reaktive Frontends. Die Integration mit dem Node-Adapter ist einfach – und fürs **Frontend** sehe ich darin meine langfristige Lösung. **Was mir fehlte:** - Komplexere Backend-Funktionalität wie Rollen, dynamische Models, Auth oder Admin-Panels fehlen oder müssen selbst gebaut werden. - Es gibt zwar ein paar Tools (z. B. Lucid, Prisma), aber der Ökosystem-Vergleich mit React zeigt: weniger Auswahl. - Kein echtes CMS-Feeling. **Fazit:** Perfekt für Frontends. Als CMS-Backend nicht geeignet. ### Strapi – Gute API, aber UI nicht meins **Pluspunkte:** - Sehr reifes Headless CMS auf Basis von Node.js. - Gute REST- und GraphQL-Schnittstellen. - Rollen-/Rechtemanagement, dynamische Content-Types, einfache Auth. **Aber:** - Das Admin-Panel wirkt auf mich visuell und UX-technisch nicht ansprechend. - Die Konfiguration ist teilweise uneinheitlich (Code vs. UI). - Etwas schwergewichtig für kleinere Projekte. **Fazit:** Technisch solide – aber ich habe mich im Admin nicht wohlgefühlt. ### PayloadCMS **Warum ich geblieben bin:** - Komplett in TypeScript. - Das Admin-Panel ist schnell, intuitiv und sehr anpassbar. - Content-Modeling über Code (statt Click UI). - Lokale Entwicklung, gute Dokumentation, offene Architektur. - Built-in Auth, Access Control, Dateiupload, Versioning etc. - Ideal für Entwickler:innen. **Fazit:** **PayloadCMS** ist genau das, was ich gesucht habe: Entwicklerfreundlich, modern, headless und API-zentriert. Es passt gut zu meinem Setup mit SvelteKit als Frontend – und ist damit mein Favorit für das Projekt. ### Beispiel-Systemarchitektur ``` +------------------------------+ | Frontend (SvelteKit) | |------------------------------| | - SvelteKit App | | - Node Adapter | | (für API-Proxy) | +-------------+----------------+ | | REST / GraphQL v +------------------------------+ | Backend (PayloadCMS) | |------------------------------| | - Payload Server (Next.js) | | - Access Control & Auth | | - Custom Hooks / Logic | | - ORM / Content Models | | - File Uploads / Admin UI | +-------------+----------------+ | v +------------------------------+ | MongoDB | |------------------------------| | - Persistente Speicherung | | von Inhalten & Usern | +------------------------------+ ``` ### Weiterführende Ressourcen - [PayloadCMS Docs](https://payloadcms.com/docs) - [SvelteKit V5 Docs](https://svelte.dev/docs) - [Filament für Laravel](https://filamentphp.com) # PayloadCMS **PayloadCMS** ist ein modernes, Headless CMS, das vollständig auf **Node.js** basiert und speziell für Entwickler:innen konzipiert ist. Es kombiniert ein leistungsfähiges Admin-Panel mit einem *code-first*-Ansatz, wodurch Inhalte, Strukturen und Logiken direkt im Code definiert werden können. ### Überblick| **Eigenschaft** | **Beschreibung** |
|---|---|
| CMS-Typ | Headless CMS |
| Backend | Node.js + Express |
| Sprache | TypeScript (auch JavaScript möglich) |
| API-Schnittstellen | REST und GraphQL |
| Admin-Oberfläche | Automatisch generiert aus dem Code |
| Authentifizierung | Integriert (JWT, Sessions, Role-based Access) |
| Datenbanken | MongoDB (Standard), **PostgreSQL / SQLite** via Kysely (experimentell) |
| ORM/Query Builder | Mongoose (MongoDB) / Kysely (SQL-DBs wie SQLite) |
| **Datenbank** | **Standard?** | **ORM / Query Layer** | **Hinweise** |
|---|---|---|---|
| MongoDB | ✅ | Mongoose | Reif & empfohlen |
| SQLite | 🔄 (ab 1.12+) | Kysely | Gut für lokale Dev |
| PostgreSQL | 🔄 (ab 1.12+) | Kysely | Für produktive SQL-Setups |
| Kriterium | SOAP | REST | GraphQL |
|---|---|---|---|
| Architekturtyp | Protokollbasiert | Architekturstil | Abfragesprache & Laufzeitumgebung |
| Transportprotokoll | HTTP, SMTP, TCP | HTTP | HTTP (meist POST) |
| Datenformat | XML | JSON, XML | JSON |
| Endpunkte | Mehrere, pro Operation | Mehrere, pro Ressource | Ein einziger Endpunkt |
| Abfrageflexibilität | Gering – festgelegte Operationen | Mittel – durch verschiedene Endpunkte | Hoch – clientseitig definierte Abfragen |
| Versionierung | Über WSDL-Dateien | Häufig über URL-Versionierung (z. B. /v1/) | Nicht erforderlich – Schema kann erweitert werden |
| Caching | Komplex, selten genutzt | Gut unterstützt durch HTTP-Caching | Eingeschränkt – abhängig von Abfragekomplexität |
| Fehlerbehandlung | Standardisierte Fehlercodes in XML | HTTP-Statuscodes + optionale Fehlermeldungen | Fehlerobjekte im JSON-Format |
| Sicherheitsmechanismen | WS-Security (z. B. XML-Signaturen) | TLS/HTTPS, OAuth, API-Keys | TLS/HTTPS, OAuth, API-Keys |
| Einsatzgebiete | Unternehmensanwendungen, Legacy-Systeme | Web-APIs, Microservices, mobile Anwendungen | Moderne SPAs, mobile Apps, datenintensive Anwendungen |
| Komplexität | Hoch – umfangreiche Spezifikationen | Mittel – abhängig vom Design | Hoch – insbesondere bei komplexen Schemas |
| Vorteil | Beschreibung |
|---|---|
| **Skalierbarkeit** | Einzelne Services lassen sich unabhängig skalieren (z. B. CPU-hungrige Module). |
| **Flexibilität** | Technologieentscheidungen können pro Dienst individuell getroffen werden. |
| **Deployment-Freiheit** | Teams können unabhängig voneinander releasen. |
| **Fehlertoleranz** | Ein Fehler in einem Dienst betrifft nicht notwendigerweise das Gesamtsystem. |
| **Teamautonomie** | Kleinere Teams können Verantwortung für „ihren“ Dienst übernehmen. |
| Nachteil / Herausforderung | Beschreibung |
|---|---|
| **Systemkomplexität** | Die Gesamtarchitektur wird komplexer, insbesondere hinsichtlich Kommunikation und Datenfluss. |
| **Testing-Aufwand** | Integrationstests und End-to-End-Tests werden aufwendiger. |
| **Verteilte Transaktionen** | ACID-Eigenschaften sind über mehrere Dienste schwer zu garantieren. |
| **Fehlende Übersicht** | Es kann schwierig sein, einen systemweiten Überblick zu behalten. |
| **Tooling & Infrastruktur** | Microservices benötigen reifes CI/CD, Observability, Logging, Monitoring. |
| Begriff | Bedeutung |
|---|---|
| **API-Gateway** | Zentrale Anlaufstelle für externe Anfragen an ein Microservice-System. |
| **Cluster** | Gruppe aus mehreren Servern, die gemeinsam eine verteilte Umgebung bilden. |
| **Container** | Leichtgewichtige Umgebung zur isolierten Ausführung von Software-Komponenten. |
| **DDD** | Domain-Driven Design – domänenzentrierter Ansatz zur Softwaremodellierung. |
| **Docker** | Plattform zur Containerisierung und zum Deployment verteilter Anwendungen. |
| **Kubernetes** | System zur automatisierten Verwaltung, Skalierung und Orchestrierung von Containern. |
| **Monolith** | Architektur, bei der die gesamte Anwendung als eine Einheit betrieben wird. |
| **Self-contained System** | Architekturansatz, bei dem jeder Dienst auch UI, Logik und Persistenz umfasst. |
| **Service Discovery** | Verfahren, mit dem Microservices einander automatisch auffinden können. |
Für weitere Informationen und tiefergehende technische Details empfiehlt sich die offiziellen Spezifikation [RFC 6455](https://tools.ietf.org/html/rfc6455) sowie die Dokumentation auf [MDN Web Docs](https://developer.mozilla.org/de/docs/Web/API/WebSockets_API).
# Message Queueing Hier ist ein umfassender Wiki-Artikel zum Thema **Message Queuing**, mit besonderem Fokus auf **RabbitMQ** als Praxisbeispiel: --- # **📬 Message Queuing – Grundlagen und Praxis mit RabbitMQ** ## **1. Einführung: Was ist Message Queuing?** Message Queuing (MQ) ist ein Kommunikationsparadigma, das es ermöglicht, Nachrichten asynchron zwischen verschiedenen Komponenten eines Systems auszutauschen. Dabei werden Nachrichten in einer Warteschlange (Queue) zwischengespeichert, bis sie von einem Empfänger (Consumer) verarbeitet werden. Dieses Modell fördert die Entkopplung von Systemkomponenten und erhöht die Skalierbarkeit und Fehlertoleranz von Anwendungen. ## **2. Vorteile von Message Queuing** - **Asynchrone Kommunikation**: Sender und Empfänger müssen nicht gleichzeitig aktiv sein. - **Entkopplung**: Komponenten können unabhängig voneinander entwickelt und betrieben werden. - **Lastverteilung**: Nachrichten können auf mehrere Empfänger verteilt werden, um die Verarbeitungslast zu verteilen. - **Fehlertoleranz**: Nachrichten bleiben in der Queue, bis sie erfolgreich verarbeitet wurden, was die Zuverlässigkeit erhöht. - **Skalierbarkeit**: Einfaches Hinzufügen weiterer Empfänger zur Verarbeitung steigender Nachrichtenmengen. ## Anwendungsfälle - **Auftragsverarbeitung**: Bestellungen werden in einer Queue gespeichert und von einem Backend-System verarbeitet. - **E-Mail-Versand**: E-Mails werden als Nachrichten in eine Queue gestellt und von einem separaten Dienst versendet. - **Log-Verarbeitung**: Anwendungslogs werden gesammelt und asynchron analysiert. - **Microservices-Kommunikation**: Services kommunizieren über Nachrichten, um lose gekoppelt zu bleiben. ## RabbitMQ – Ein Praxisbeispiel RabbitMQ ist ein weit verbreiteter, quelloffener Message Broker, der das **Advanced Message Queuing Protocol (AMQP)** implementiert. Es ermöglicht das Senden, Empfangen und Weiterleiten von Nachrichten zwischen Anwendungen oder Diensten. ### Grundkonzepte - **Producer**: Erzeugt und sendet Nachrichten. - **Exchange**: Empfängt Nachrichten vom Producer und leitet sie gemäß bestimmter Regeln weiter. - **Queue**: Speichert Nachrichten, bis sie vom Consumer abgeholt werden. - **Consumer**: Empfängt und verarbeitet Nachrichten aus der Queue. ### Exchange-Typen - **Direct**: Leitet Nachrichten basierend auf einer exakten Routing-Key-Übereinstimmung weiter. - **Fanout**: Leitet Nachrichten an alle gebundenen Queues weiter, unabhängig vom Routing Key. - **Topic**: Leitet Nachrichten basierend auf Musterabgleich des Routing Keys weiter. - **Headers**: Leitet Nachrichten basierend auf Header-Attributen weiter. ## Implementierung mit RabbitMQ ### Installation RabbitMQ kann lokal installiert oder über Docker bereitgestellt werden. Eine einfache Möglichkeit ist die Verwendung des offiziellen Docker-Images: ``` docker run -d --hostname my-rabbit --name some-rabbit -p 5672:5672 -p 15672:15672 rabbitmq:3-management ``` Dies startet RabbitMQ mit dem Management-Plugin, das über http://localhost:15672 erreichbar ist. ### Beispiel: Nachricht senden und empfangen mit Python Verwendung der pika-Bibliothek: **Producer (Sender):** ``` import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='hello') channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close() ``` **Consumer (Empfänger):** ``` import pika def callback(ch, method, properties, body): print(f" [x] Received {body}") connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='hello') channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() ``` Diese einfachen Beispiele zeigen, wie Nachrichten in eine Queue gesendet und von dort empfangen werden können. ## Zusammenfassung Message Queuing ist ein leistungsfähiges Muster zur asynchronen Kommunikation in verteilten Systemen. RabbitMQ bietet eine robuste und flexible Implementierung dieses Musters und ist in vielen Szenarien einsetzbar, von einfachen Anwendungen bis hin zu komplexen Microservices-Architekturen. Weiterführende Ressourcen: - [RabbitMQ Tutorials](https://www.rabbitmq.com/tutorials) - [RabbitMQ Dokumentation](https://www.rabbitmq.com/documentation.html) - [AMQP 0-9-1 Referenz](https://www.rabbitmq.com/amqp-0-9-1-reference.html) # Testing # Oberflächentests mit Playwright ### Einleitung Oberflächentests (UI-Tests) stellen sicher, dass Webanwendungen sich so verhalten, wie es Benutzer erwarten – unabhängig vom internen Code. Mit **Playwright** steht ein modernes, mächtiges Test-Framework zur Verfügung, das speziell für dynamische Web-UIs entwickelt wurde. Dieser Artikel stellt Playwright vor, zeigt seinen Einsatz in einem typischen Projekt mit SvelteKit und vergleicht es mit Alternativen wie Cypress und Selenium. Darüber hinaus werden praktische Strategien zur Teststruktur, Fehlervermeidung und Debugging vermittelt. --- ### Was ist Playwright? Playwright ist ein von Microsoft entwickeltes Open-Source-Tool für **UI-Tests** von Webanwendungen. Tests werden in echten Browserinstanzen (Chromium, Firefox, WebKit) ausgeführt und über DevTools-Protokolle gesteuert. Besonders hervorzuheben sind: - Unterstützung mehrerer Browser - Automatische Warte-Mechanismen - Netzwerk-Interception, Screenshot, Tracing, Debugging --- ### Typischer Playwright-Workflow Playwright erkennt standardmäßig alle Testdateien mit den Endungen `.spec.ts` oder `.test.ts`. Es ist also üblich, Testdateien nach dem Schema `xyz.spec.ts` zu benennen. Dies ist keine Pflicht, aber eine empfohlene Konvention, da sie vom Test-Runner automatisch erkannt wird. Ein vollständiger Testdurchlauf mit Playwright besteht in der Regel aus drei Schritten: 1. **Test schreiben** - Der Test wird als JavaScript- oder TypeScript-Datei im `e2e/`-Verzeichnis abgelegt. - Beispiel: ```javascript test('zeigt Loginformular', async ({ page }) => { await page.goto('/login'); await expect(page.locator('form')).toBeVisible(); }); ``` 2. **Test ausführen** - Im Terminal ausführen: ```bash npx playwright test ``` - Optional: Nur bestimmte Tests oder Dateien ausführen: ```bash npx playwright test login.spec.ts ``` 3. **Ergebnisse analysieren** - Playwright gibt im Terminal an, ob Tests bestanden oder fehlgeschlagen sind. - Bei Fehlern: - Trace-Dateien oder Screenshots analysieren - Optional: `--debug` oder `--trace on` verwenden Beispiel: ```bash npx playwright show-trace trace.zip ``` Dieser Workflow ist die Grundlage für einfache lokale Tests, funktioniert aber auch identisch in CI/CD-Umgebungen (z. B. GitHub Actions). --- #### Automatische Warte-Mechanismen Playwright wartet **intelligent und automatisch** auf Ereignisse im DOM. Das bedeutet: Wenn du z. B. ein Element anklickst oder eine Seite neu lädst, wartet Playwright so lange, bis die Seite bereit ist (Ladezustand, Sichtbarkeit, Interaktivität), **ohne dass du explizit `wait`-Befehle schreiben musst**. Das reduziert Fehler durch Timing-Probleme erheblich und macht Tests stabiler als bei älteren Tools wie Selenium. Beispiel: ```ts await page.click('text=Speichern'); // wartet intern, bis der Button sichtbar & klickbar ist ``` #### Netzwerk-Interception Mit Playwright kannst du **HTTP-Anfragen abfangen und manipulieren**, bevor sie den Server erreichen oder nachdem sie empfangen wurden. Das ermöglicht z. B.: - das **Mocken von Backend-Antworten** - das **Blockieren von Requests** (z. B. zu externen APIs) - das **Simulieren von Fehlerzuständen** (z. B. 500er-Fehler) Beispiel: ```ts await page.route('**/api/user', route => { route.fulfill({ status: 200, body: JSON.stringify({ name: 'Testuser' }) }); }); ``` #### Screenshot Playwright kann jederzeit einen Screenshot vom aktuellen Zustand der Seite aufnehmen – z. B. zur **Fehlerdokumentation**, zur visuellen Regression oder einfach als Debugging-Hilfe. Das ist besonders nützlich bei CI-Testläufen, wenn ein Test fehlschlägt. Beispiel: ```ts await page.screenshot({ path: 'screenshot.png', fullPage: true }); ``` #### Tracing Das **Tracing-System von Playwright** erstellt eine vollständige Aufzeichnung eines Testlaufs. Die generierte Datei (`trace.zip`) kann mit dem Trace Viewer analysiert werden. Dieser zeigt: - DOM-Zustände und Screenshots nach jeder Aktion - Klickpfade und Zeitverlauf - Netzwerkanfragen und -antworten - Konsolenausgaben und Fehler Der Trace Viewer eignet sich ideal zum Debuggen, wenn Tests unerwartet fehlschlagen oder das Timing von UI-Interaktionen unklar ist. **Verwendung:** ```bash npx playwright test --trace on npx playwright show-trace trace.zip ``` Das Tool ist interaktiv und CI-fähig – es gehört zu den zentralen Debugging-Funktionen von Playwright. --- #### HTML-Report Playwright enthält standardmäßig einen HTML-Reporter, der nach einem Testlauf einen interaktiven Bericht erzeugen kann. **Verwendung:** ```bash npx playwright test --reporter=html npx playwright show-report ``` Dabei entsteht ein Verzeichnis `playwright-report/`, in dem die Testergebnisse als durchklickbarer HTML-Bericht gespeichert werden. Der Report enthält: - Status jedes Tests (✔ / ✖) - Detaillierte Fehlerbeschreibung (Stacktrace) - Screenshots bei Fehlern - Trace-Links, sofern aktiviert **Hinweis:** Reporter lassen sich auch dauerhaft in `playwright.config.ts` setzen: ```ts reporter: ['list', 'html'] ``` Der HTML-Report eignet sich besonders gut für Reviews, Testprotokolle oder zur Weitergabe an Stakeholder. Das **Tracing-System von Playwright** erstellt eine vollständige Aufzeichnung eines Testlaufs. Die generierte Datei (`trace.zip`) kann mit dem Trace Viewer analysiert werden. Dieser zeigt: - DOM-Zustände und Screenshots nach jeder Aktion - Klickpfade und Zeitverlauf - Netzwerkanfragen und -antworten - Konsolenausgaben und Fehler Der Trace Viewer eignet sich ideal zum Debuggen, wenn Tests unerwartet fehlschlagen oder das Timing von UI-Interaktionen unklar ist. **Verwendung:** ```bash npx playwright test --trace on npx playwright show-trace trace.zip ``` Das Tool ist interaktiv und CI-fähig – es gehört zu den zentralen Debugging-Funktionen von Playwright. Das **Tracing-System von Playwright** erstellt einen kompletten „Film“ eines fehlgeschlagenen Testlaufs: Es enthält Informationen über: - alle DOM-Änderungen - Netzwerk-Anfragen - Konsolenmeldungen - Screenshots und Zeitleisten Diese Daten können im **Playwright Trace Viewer** visuell nachvollzogen werden – ideal zum Debuggen komplexer Fehler in CI/CD. ```bash npx playwright test --trace on npx playwright show-trace trace.zip ``` #### Debugging Zusätzlich zum Tracing bietet Playwright u. a.: - einen **Inspector** (GUI zum „Step-by-Step-Debuggen“ im Browser) - `codegen` zur **Aufzeichnung von Tests** - **Pause-Funktion** für interaktives Testen (`page.pause()`) Beispiel: ```ts await page.pause(); // öffnet Debugger-Fenster mit DOM-Explorer ``` --- ### Integration in moderne Frameworks Ein großer Pluspunkt ist die **nahtlose Integration in moderne Toolchains**. Bei der Installation eines SvelteKit-Projekts wird Playwright beispielsweise direkt mit angeboten. Es ist kein manueller Konfigurationsaufwand nötig. --- ### Typische Teststruktur Playwright kann Tests in mehreren Browsern ausführen – etwa in Chromium, Firefox oder WebKit. Wird in der `playwright.config.ts` jedoch kein `projects`-Abschnitt definiert, wie z. B. im SvelteKit-Starter, verwendet Playwright **standardmäßig nur Chromium**. Das reicht für viele Szenarien – schränkt aber die Cross-Browser-Testbarkeit ein. Möchte man Tests zusätzlich in Firefox und WebKit durchführen, lässt sich die Konfiguration um `projects` erweitern: ```javascript projects: [ { name: 'chromium', use: { ...devices['Desktop Chrome'] } }, { name: 'firefox', use: { ...devices['Desktop Firefox'] } }, { name: 'webkit', use: { ...devices['Desktop Safari'] } }, ] ``` Playwright führt die Tests dann automatisch für alle angegebenen Browser durch – entweder nacheinander oder parallel, je nach Konfiguration. So lassen sich UI-Komponenten und Workflows direkt in allen wichtigen Rendering-Engines verifizieren. Playwright führt die Tests dann automatisch für alle angegebenen Browser durch – entweder nacheinander oder parallel, je nach Konfiguration. So lassen sich UI-Komponenten und Workflows direkt in allen wichtigen Rendering-Engines verifizieren. Playwright-Konfigurationen werden in der Datei `playwright.config.ts` definiert. Besonders praktisch ist dabei die Möglichkeit, den lokalen Server automatisch zu starten, bevor die Tests ausgeführt werden: ```javascript import { defineConfig } from '@playwright/test'; export default defineConfig({ webServer: { command: 'npm run build && npm run preview', port: 4173 }, testDir: 'e2e' }); ``` - `command` startet den lokalen Server, z. B. den SvelteKit-Preview-Modus. - `port` legt fest, wo der Test-Runner auf die Anwendung wartet. - `testDir` gibt das Verzeichnis an, in dem die Tests gespeichert sind. Diese automatische Startlogik ist besonders hilfreich für CI/CD, da kein separater Serverlauf erforderlich ist. Wer möchte, kann hier auch eigene Kommandos oder Ports verwenden – etwa um eine andere Umgebung zu testen oder eine API-Instanz parallel zu starten. Playwright sucht standardmäßig in dem Ordner nach Tests, in dem sich deine `playwright.config.ts` befindet. Zudem erkennt es von sich aus alle Dateien mit den Endungen `.spec.ts`, `.test.ts`, `.spec.js`, `.test.js`. Viele Framework-Vorlagen – z. B. SvelteKit – legen hierfür das Verzeichnis `e2e/` an. Dies ist aber keine Vorgabe seitens Playwright, sondern eine Empfehlung, um **Frontend- und End-to-End-Tests (E2E)** strukturiert zu trennen. Du kannst stattdessen auch beliebige andere Verzeichnisse nutzen (z. B. `tests/`, `ui-tests/`), solange sie sich im selben Verzeichnis wie `playwright.config.ts` befinden – oder du `testDir` in der Konfiguration entsprechend anpasst. Nach dem Setup legt Playwright ein `e2e/`-Verzeichnis an (z. B. durch SvelteKit). Ein einfacher Test könnte so aussehen: ```javascript test('zeigt ein leeres Board mit 6x7 Zellen', async ({ page }) => { await page.goto('/'); const cells = await page.locator('[data-test^=cell-]'); await expect(cells).toHaveCount(6 * 7); }); ``` Häufig verwendete Befehle: - `page.click(selector)` – Klick auf ein Element - `page.fill(selector, text)` – Eingabe simulieren - `expect(locator).toHaveText()` – Zustand prüfen - `page.screenshot()` – Fehler sichtbar machen - `test.beforeEach()` – Setup vor jedem Test Nach dem Setup legt Playwright ein `e2e/`-Verzeichnis an. Ein einfacher Test könnte so aussehen: ```javascript test('zeigt ein leeres Board mit 6x7 Zellen', async ({ page }) => { await page.goto('/'); const cells = await page.locator('[data-test^=cell-]'); await expect(cells).toHaveCount(6 * 7); }); ``` Häufig verwendete Befehle: - `page.click(selector)` – Klick auf ein Element - `page.fill(selector, text)` – Eingabe simulieren - `expect(locator).toHaveText()` – Zustand prüfen - `page.screenshot()` – Fehler sichtbar machen - `test.beforeEach()` – Setup vor jedem Test --- ### Vergleich: Playwright, Cypress, Selenium| Merkmal | Playwright | Cypress | Selenium |
|---|---|---|---|
| Ausführungskontext | Außerhalb des Browsers über native DevTools-Protokolle | Im Browser | Extern via WebDriver |
| Sprachen | JS/TS, Python, C#, Java | Nur JS/TS | Viele (Java, Python, etc.) |
| Browser-Support | Chromium, Firefox, WebKit | Chromium-basiert, Firefox (beta) | Alle, inkl. IE |
| Multi-Tab, Multi-Window | Voll unterstützt | Eingeschränkt | Möglich, aber komplex |
| Netzwerk-Interception | Einfach via `page.route()` | Eingeschränkt | Aufwendig |
| Debugging | Trace Viewer, Screenshots, CLI | Zeitreise im Browser, GUI | Schwerfällig |
| Setup-Aufwand | Minimal (bei modernen Frameworks) | Mittel | Hoch |